Python Scrapy로 디씨인사이드 갤러리 크롤링하기
시작하며
게으른 수니는 일일이 게시물을 확인하기가 귀찮습니다. 하지만 사진은 보고싶지요. 디씨인사이드 비 갤러리 개념글의 사진만 모아진 페이지가 있으면 참 좋겠다고 생각하던 찰나, 동료 개발자의 원데이 크롤링 세미나를 듣고 직접 만들어 보기로 했습니다. 제 수준을 먼저 말씀드리자면 UI 개발 3년차이고 파이썬은 처음 써봅니다. Hello World를 찍을 수 있는 수준이 별 1개라고 쳤을 때, 이 크롤러 개발 난이도는 별 2개 정도 되는 것 같습니다. 튜토리얼을 무리없이 따라 할 수 있다면 디씨인사이드 갤러리 크롤링도 쉽게 하실 수 있을 겁니다.
사용기술
- Scrapy(Tutorial) : 파이썬 크롤링 프레임워크
- Masonry.js : 레이아웃 정렬을 위한 플러그인
- ImagesLoaded.js : 이미지 로드 후 레이아웃 재정렬을 위해 필요한 플러그인
개발과정
0. 선행학습 : 개발 환경 셋팅 및 기초 튜토리얼
튜토리얼을 완료 한 시점을 기준으로 포스팅하겠습니다.
1. 비 갤러리 개념글 크롤링하여 json 파일로 뽑기
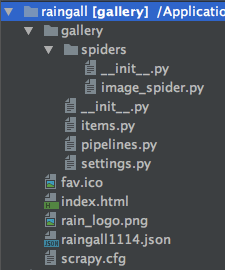
[ 파일 디렉토리 ]
# image_spider.py
# https://doc.scrapy.org/en/latest/intro/tutorial.html
import scrapy
class ImageSpider(scrapy.Spider):
name = "raingall"
start_urls = ['http://gall.dcinside.com/board/lists/?id=rain&page=1&exception_mode=recommend']
# 현재 페이지의 공지글을 제외하고 게시판의 모든 글을 추출
def parse(self, response):
for post in response.css('td.t_subject'):
next_post = post.css('a:not(.icon_notice)::attr(href)').extract_first()
if next_post is not None:
next_post = response.urljoin(next_post)
yield scrapy.Request(next_post, callback=self.parse_img)
# 현재 페이지가 완료되면 다음 페이지로 넘어가서 추출
next_page = response.css('div#dgn_btn_paging a.on+a::attr(href)').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
# 게시글안의 이미지를 모두 추출
def parse_img(self, response):
for link in response.css('div.s_write'):
post_link = response.url
img_list = link.css('img::attr(src)').extract()
# json 포맷으로 저장
for img in img_list:
if img is not None:
yield {
'info': {
'img': img,
'link': post_link
}
}
scrapy crawl raingall -o raingall1114.json
2. 이미지 갤러리 만들기
<!-- index.html -->
<div id="gallery" class="grid">
</div>
<button id="btn-more" class="btn-more">Load More</button>
/* script in index.html */
// masonry layout init
var $grid = $('.grid').masonry({
itemSelector: '.item',
columnWidth: 10,
isFitWidth: true
});
// json 파일 가져와서 30개씩 무한 로딩
$.getJSON('raingall1114.json', function(data){
var length = data.length;
console.log('data.length : '+length);
// 첫 30개 이미지 로드
loadMore(data, 30);
// 스크롤이 있을 경우 페이지 하단에서 무한 로딩
$(window).scroll(function(){
if ($(window).scrollTop() == $(document).height() - $(window).height()) {
loadMore(data, 30);
}
});
// 스크롤이 없을 경우에는 버튼을 눌러 더보기
$('#btn-more').click(function(){
loadMore(data, 30);
});
});
var startNum = 0;
function loadMore(data, n){
var endNum = startNum + n;
for(var i=startNum; i<endNum; i++){
var info = data[i].info;
var link = info.link;
var url = info.img;
// http로 시작하는 절대 경로 and zzbang(짤방)이 아닌 경우 and 스태틱 리소스가 아닌 경우
if(url.indexOf('http://') > -1 && url.indexOf('zzbang')<0 && url.indexOf('static')<0){
// url 치환 (dcimg1, dcimg2로 시작하는 서버는 접근 불가 - 403 forbidden)
if(url.indexOf('dcimg1') > -1){
url = url.replace('dcimg1', 'image');
}
else if(url.indexOf('dcimg2') > -1){
url = url.replace('dcimg2', 'image');
}
// 하나씩 메이슨리 레이아웃에 추가
var $item = $('<div class="item"><a href="'+link+'" target="_blank"><img src="'+url+'"></a></div>');
$grid.append($item).masonry('appended', $item);
// 이미지 로드 완료 시 메이슨리 레이아웃 재정렬
$item.imagesLoaded().progress(function(){
$grid.masonry('layout');
});
}
}
startNum = endNum;
// 스크롤이 생기면 'load more' 버튼 가리기
if ($(document).height() > $(window).height()) {
$('#btn-more').hide();
}
}
2-1. 이슈
메이슨리 레이아웃은 기본적으로 고정된 width/height를 가진 요소에 한해서 정렬을 해줍니다. 따라서 이미지 로드가 느릴 경우는 정상적으로 정렬을 할 수가 없습니다. 이미지가 완전히 로드 된 후에 높이를 알 수 있기 때문입니다. 이 부분을 해결해주기 위해 아래 스크린샷에서 말하는 바와 같이 ImagesLoaded.js를 사용해야 합니다.
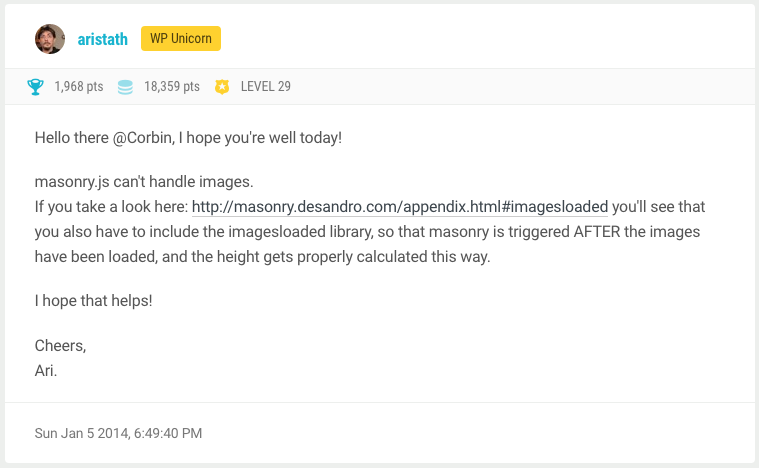
2-2. 이슈2
dcimg1, dcimg2 로 시작하는 서버는 접근 불가 (403 forbidden)여서 image 로 바꿔주니 이미지를 가져올 수 있었습니다.
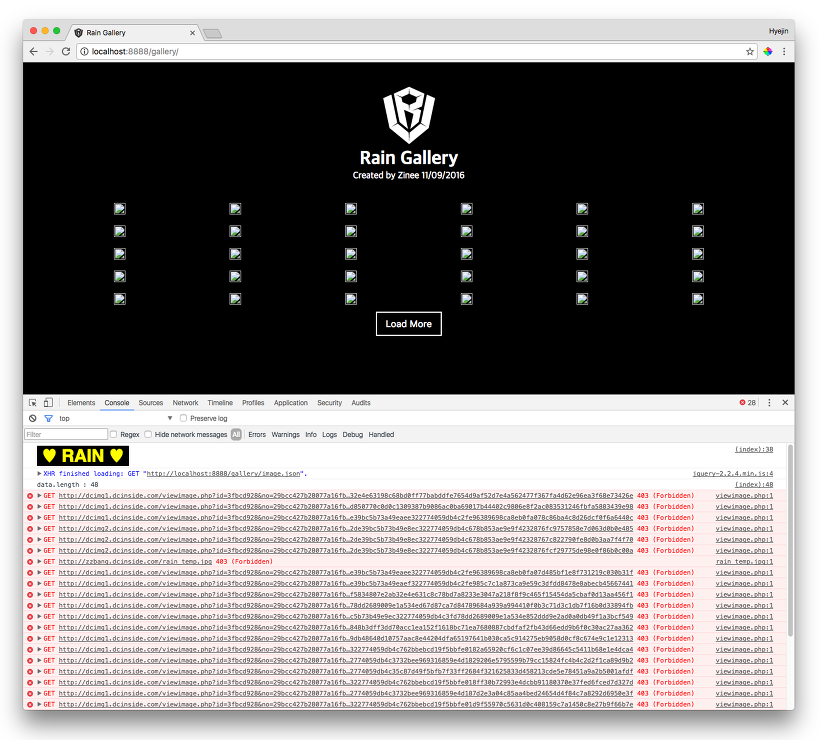
결과화면

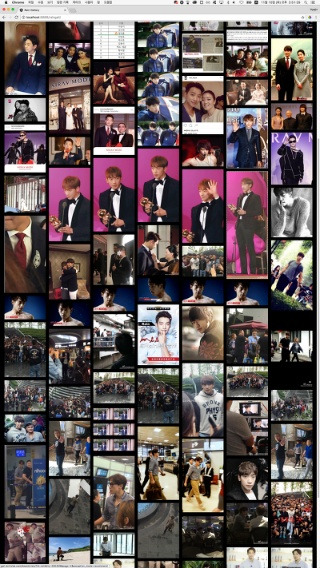
코멘트
진정한 덕업일치의 사이드 프로젝트라 재미있게 만들 수 있었습니다. 예전부터 생각만 했던 것을 직접 만들어 보았다는 점에서 뿌듯합니다. css 선택자를 사용하는 부분에 있어서는 기존 지식을 적용할 수 있어서 수월했습니다.
파이썬은 처음이어서 기초 문법도 습득하지 않은 채 튜토리얼에 나와 있는 코드만을 이용해서 짜서 부족한 부분이 많습니다. 특히 파싱한 이미지 주소 치환이나 특정 텍스트 포함시 배제 하는 것 등을 처음에 크롤링 할때 처리하는게 맞다고 생각합니다. 그런데 파이썬이 익숙치 않아서 자바스크립트로 처리한 점이 마음에 걸리네요. 파이썬 기초 공부 좀 한 뒤에 리팩토링 하겠다고 다짐(...) 해봅니다. beautifulsoup4 라는 다른 크롤링 프레임워크도 있다고 하니 그것도 사용해 보고싶습니다.
크롤링이 핵심이긴 한데 긁어온 데이터를 보기 좋게 뿌려주는 것이 오히려 더 오랜 시간을 잡아 먹었습니다. 이래서 프론트엔드를 싫어하시는 분들이 계신 건가 잠깐 그 분들의 마음이 이해가 갔어요. 메이슨리 레이아웃이 어떤 건지는 알고 있었지만 실 프로젝트에 사용해 본적은 없었는데, 이번 기회를 통해 써 볼 수 있어서 좋았습니다.
메이슨리 대신 css flexbox로 레이아웃을 잡아보았으나 이미지 간의 높이 차이가 많이 나서 하단으로 갈 수록 정렬이 많이 망가지는 것을 확인했습니다. 플렉스 박스는 고만고만한 높이의 요소들을 정렬할 때 쓰는 것이 좋다는 점도 알았습니다. 생각보다 이것저것 쏠쏠하게 배운 사이드 프로젝트였습니다. 크롤링의 세계로 이끌어주신 Selo님께 감사하며 마치겠습니다!